Recently, I took the new Firebase 3.0 SDK for a ride, in building a small web app called CodeBySide, an app to help you compare multiple code snippets from different programming languages, side by side.
See below for a practical, in-depth consideration of the possibilities behind Firebase Rules in the video, The Key to Firebase Security.
In the process of building CodeBySide, I decided to entirely use Firebase SDK related features. Authentication, Realtime Database, and Firebase Hosting are the three key features of Firebase I currently employ on the web app.
Firebase: New but Strong
Undoubtedly, Firebase is new relatively, however making great and wide strides in helping lone freelance developers (such as myself) get up and running quickly, without having to do all the plumbing works over and over.
In addition, Firebase allows me to think less of controversial issues such as how secured my authentication is and whether I’ll be storing user data and how I am storing them etc. Even better, I can throw in OAuth from different third-party providers seamless in less than 30 seconds, literally!
Recently finished with MadeWithFirebase.com, a place to showcase apps built on top of the luxury Firebase provides.
Although there are many great frameworks or packages out there responsible for handling sometimes delicate tasks like Authentication and Authorization, namely Passport.js for Nodejs or AllAuth for Django, having such tasks abstracted away neatly and seamlessly is a priceless giveaway well appreciated.
What’s more, the price point is mind-blowingly affordable. The cost? 0$ for starters. With Firebase, there’s the ‘Fire’ part. And yes, for starters, the free package is considered a ‘Sparkle’.
This package comes with all there is with Firebase. At least for an app the size of CodeBySide, there is no need to turn on the forest fire yet, but all in all, the service, documentation, and support is impressive.
Firebase support helped me with an issue. Their assistance throughout the process got me so excited of which I share the details on SO.
At this point, I wish to say I give Firebase all the stars possible, all the stars, except I have to take away one or two stars from ‘the’ all stars I just gave them.
Below are what I personally realized missing. As a matter of fact, depending on one’s use cases, the list I present below might not apply.
However, I believe should these be included with Firebase, Ooh it will get much better, and perhaps go to the extent of blowing the other IaaS and or SaaS providers out of the water for good.
Native Offline Support (Web)
It is dead simple: Want to build a Progressive Web App with Firebase? I’m sorry, you can’t.
Firebase web has no support for offline storage. Although data you visit are readily available when the internet goes off, a quick refresh means everything will be gone.
If you’re like me, excited about PWAs, then calm down, because as it stands now, offline support ain’t available. You’ll have to find your own workarounds. Pouch DB <==> Couch DB might be your thing, which you might wanna explore.
Although I do not feel locked into Firebase’s ecosystem (I can export my tiny database over to Couch DB), the lack of offline capabilities is what #ICantThinkFar.
Google’s everywhere these days pushing PWAs, yet their own platform has no support for the ‘future’, fortunately happening now.
Know this, as you dive into Firebase for real!
Search
The ability to search your documents is not possible with the current state of Firebase natively. I say natively because there is a way to use Elastic search plugged in to run queries against your real-time database.
Although this seems like a pretty straightforward process for the gurus who type 50 lines of code per minute with a single finger, the dumb-header like myself aren’t ready for such a ride.
However, many who build simple projects and only probably do so for learning purposes at this time with their apps might not find it worth the work of trying to spin up an Elastic search implementation just to scan through a realtime Firebase database of fewer than 10 documents from a single user.
How the search feature would be implemented, I have no idea. But I believe it won’t be a feature far-fetched. Obviously, Firebase is young, and I guess such a feature is already in the pipeline or might be soon.
I can’t wait to see basic search functionality exposed for the end user/developer to tap into. It might be a great solution for small-medium scale web apps. For the power enterprises looking to perform tens of thousands of search queries every minute, they could easily resort to using the industry standard, Elastic search.
Depending on how great the native Firebase Search becomes, maybe one might not need Elastic search at all.
Aggregation
The ability to aggregate your data from your database is key. In fact, I do not know of any great storage backend without some sort of an Aggregation Framework.
MongoDB has one of the best (if not the only best) aggregation framework out there one could ever have with a NoSQL-like storage backend.
To the extent, that part is called ‘Framework’ gives you an idea to what extent MongoDB’s Aggregation native aggregation support can take you.
It is efficient, fast and fine-tuned to the core with support from all the available clients.
Was this a lecture on MongoDB? No! In fact, Firebase Realtime Database could do with a form of aggregation ‘framework’.
Currently, Realtime Database only stores and allows retrieving data and nothing else more. Maybe the Realtime DB has some other tricks under its sleeves, but as much as I am aware of, there is no support for Aggregation.
[wp_ad_camp_1]
So you’re thinking of finding the number of users you have registered under the your.db.url/users/ endpoint in Realtime DB? At the moment, you could use nothing like say,
DatabaseRef.child('users').count()
Or perhaps you wish to find the average years of all your registered users who have added their age. Perhaps you’re thinking along the lines like:
DatabaseRef.child('users').orderByValue('age').average()
Well, you can’t! Of course, the above samples are way too oversimplified. However, I hope you get my point, which is simple: Aggregating data at the moment in Firebase is damn complex than it should be.
Damn complex? Which means one can? Yep, you can. You could set up a small node server tied into your Firebase DB URL endpoint, listening in on child_added and or child_changed events to specific parts and probably feeding back certain computed values after processed on your node server back to the Firebase DB.
In that case, should a user request for the average age of all users, well, you have already computed that value which is probably standing somewhere under your.db.url/aggregation that the user picks up.
How many sentences did I use to describe the workaround? Would it work? I don’t know for sure. I haven’t tried it myself, but theoretically, I guess that should be it for now.
But, imagine how many opportunities will open up, should Aggregation be added to Firebase natively. In that case, your iOS, Android, Web and AngularFire all could benefit from this robust unshakable, well-tested framework for handling all your aggregation needs.
Just as Firebase has joined the road to ease the workload of developers, allowing them to concentrate on building and designing their apps, without having to worry about any extra stuff of that sort, aggregation would mean a big game changer.
How easy will the addition of aggregation to Firebase Database be? And about the computational toll on Google servers?
Well, for a start, MongoDB allows holding of not more than 100 MB of documents in aggregation pipeline. That way, Firebase could set theirs too, say 20 MB max for Sparkle packages, then a price fee for higher aggregation pipeline documents size.
Does the current Database design of Firebase allow for aggregation easily? Maybe! Maybe not, which brings me to the next point.
Database Rules
Under this section, I will be brief, as I laid out my thoughts relating to how Database Rules are designed in Firebase in my previous post.
Structuring your database data probably is important as what you put in them or how your front-end looks. A bad data structure in your database could hinder the app speed to some extent sometimes (or most times?).
Many who start with Firebase Database come up with many questions such as, ‘How does Firebase not confuse who sees my personal info I add?’, ‘Won’t someone delete what I add?’ and so on.
Firebase Database has a very nice solution: Rules. Database rules apply whenever a request to an endpoint comes in. This rule will ensure the incoming request from whoever or whatever it is, has the right, and or is authorized to continue the task about to happen, be it read or write.
Although this idea sounds great, going deeper to learn how it has been designed to apply the rules might seem straightforward at first, until you start structuring your data and you begin to nest. Did I mention nest?
Look at this data structure
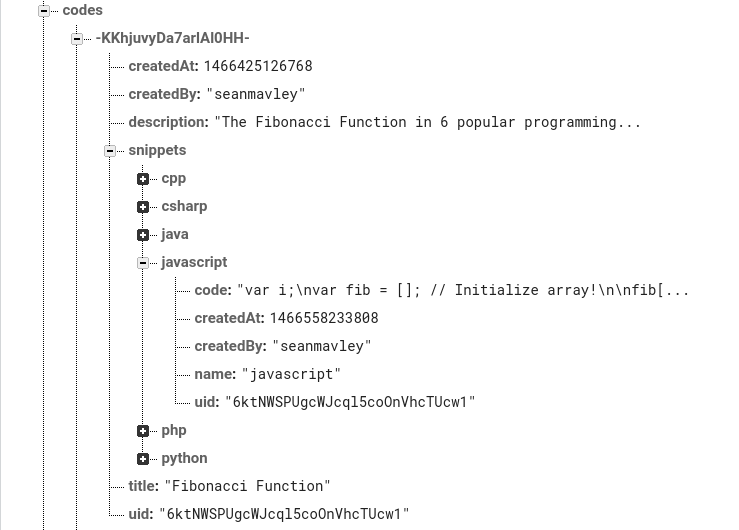
At that moment when you start applying rules to a data structure like the above is when you realize how limiting Firebase Database Rules at the moment are.
For starters, Firebase Rules do cascade, as in, a rule you set at a higher hierarchy in a data structure, runs throughout until the end of that node and its subtree and overrides any rule that tries to revoke the one already set. Final!
According to the official docs:
Note: Shallower security rules override rules at deeper paths. Child rules can only grant additional privileges to what parent nodes have already declared. They cannot revoke a read or write privilege.
The other post I link has an example, but with the above data structure, below are the summary of issues:
- Firebase rules DO cascade. Thus…
- When I apply a
.read: trueto the/codes/endpoint, EVERYTHING under that node, irrespective of any rules applied, WILL remain readable by ANYONE. - When I apply a
.write: trueto the/codes/endpoint, EVERYTHING under that node, irrespective of any rules applied, WILL remain writable by ANYONE.
So you think you’re smart? Well, how about applying the specific rules I want to the /codes/-uid/snippets/ parts for instance? In that scenario, this is what will happen:
- Firebase rules DO cascade. Thus…
- An
.writeor.readrule applied to a specific endpoint, in this case,/code/-uid/snippetswill hold should any read/write need to happen in that specific area. However…. - You will NOT be able to write or read either
/codes/or/codes/-uid/, ONLY data at or below/code/-uid/snippets
Oooh, then lemme apply specific rules to the /codes/ and different ones to the endpoints that follow?
Well, my brethren, Firebase Rules DO CASCADE unconditionally!

What should you do?
Structure your data, so that they don’t conflict with how Firebase Rules work. I ended up reworking my data structure above, bringing out the snippets/ to form their own endpoint on the root of the DB URL.
Instead of a strict top-to-down CASCADE in firebase rules, what do you think of Rules Accumulation? I explain what I mean by that more in the other post.
Even better, a markup indicating what rule should apply from top to down, and specific rules for specific tasks. So something like this:
Eventually, this is how I was expecting to do the rules (just indicating the effect in English):
{
"rules": {
"codes": {
".read": "anyone",
".write": "if logged in",
},
"snippets": {
// ".entire": "auth != null",
".read": "anyone",
".write": "if logged in && auth.uid matches data.uid"
"$snipId": {
"$language": {
".write": "logged in, first come first create, and only first allowed to edit"
}
}
}
}
The above rules approach captures exactly what Firebase rules should evolve to behave, at least.
- Rule for ‘snippets’ apply to snippets and anything hitting that specific end point
- Rule for ‘snippets/snipId’ apply to that endpoint specifically
Maybe bonus:
- Then perhaps, a rule called
.entirewhich will apply to any node downstairs a particular endpoint, so in the above, every request downstairs of snippets should happen by a logged in user. Of course, this doesn’t exist, but something like that could make rules more flexible giving specific control when needed, and generic rules when wanted.
I find the current state of Firebase Rules ridiculous, considering Firebase Database supports up to 32 data nesting structure. Of what use is nesting beyond even 3 when rules DO cascade?
UPDATE 21: For a practical understanding of Firebase Rules and how simple they are to implement, see the video below from this year’s I/O. It was an eye-opener for me, and if I had watched that video earlier before approaching Firebase, I believe my understanding would have been better.
I highly recommend. About 45 minutes in length, but trust me, you’ll love it!
Conclusion
Except the Aggregation and Search missing in Firebase which can or might be hard to pull off on your own, designing a data structure that is easy can save you, not just from only the snare of Firebase Database Rules, but from the even bigger challenge of designing a database structure that is easy to scale.
I am still exploring Firebase 3.0, and will update this post as and when I come across features I wish they are or become part of Firebase in the near future.
Lemme know what you miss most about Firebase in the comments below.
See you in the next one!